Stable DiffusionをGoogle Colaboratoryで実行してみたので備忘録として投稿します。
Google Colaboratoryに接続、セッション起動
新しいnotobookを開きます。
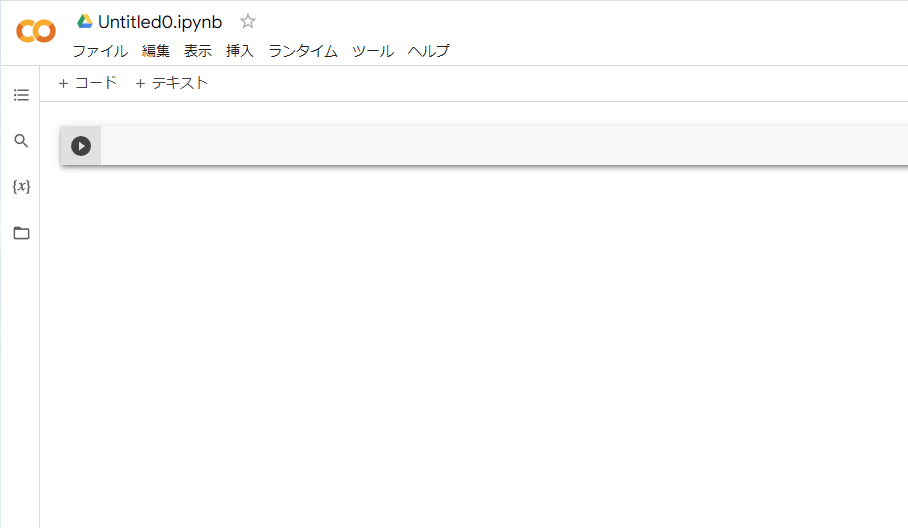
右上の「接続」の隣の▼をクリックして、「リソースの表示」を選択します。
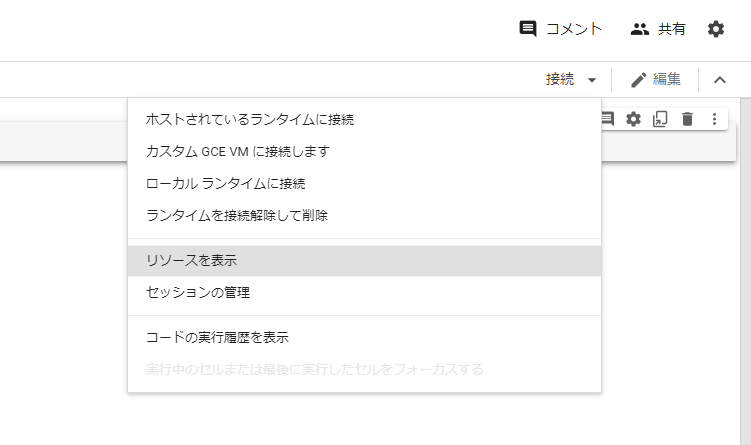
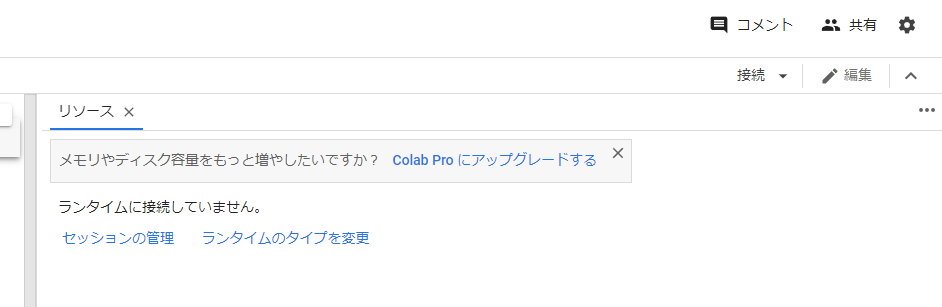
「ランタイムのタイプを変更」を選択します。
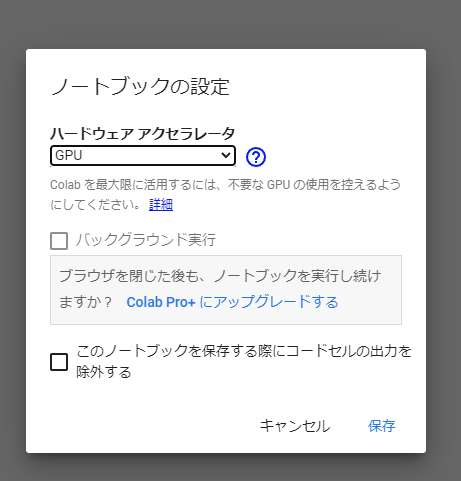
「ハードウェアアクセラレータ」を「GPU」に変更して、保存をクリック。
最後に、右上の「接続」をクリックします。
これで、セッション関係の設定は完了です。
パッケージインストール
ここからは下記リンク先に従って実行します。

CompVis/stable-diffusion-v1-4 · Hugging Face
We’re on a journey to advance and democratize artificial intelligence through open source and open science.
huggingface.co
pipコマンドで必要なパッケージをインストールします。
!pip install --upgrade diffusers transformers scipyLooking in indexes: https://pypi.org/simple, https://us-python.pkg.dev/colab-wheels/public/simple/
Collecting diffusers
Downloading diffusers-0.2.4-py3-none-any.whl (112 kB)
|████████████████████████████████| 112 kB 26.8 MB/s
Collecting transformers
Downloading transformers-4.21.1-py3-none-any.whl (4.7 MB)
|████████████████████████████████| 4.7 MB 61.5 MB/s
Requirement already satisfied: scipy in /usr/local/lib/python3.7/dist-packages (1.7.3)
Requirement already satisfied: torch>=1.4 in /usr/local/lib/python3.7/dist-packages (from diffusers) (1.12.1+cu113)
Requirement already satisfied: importlib-metadata in /usr/local/lib/python3.7/dist-packages (from diffusers) (4.12.0)
Requirement already satisfied: requests in /usr/local/lib/python3.7/dist-packages (from diffusers) (2.23.0)
Collecting huggingface-hub<1.0,>=0.8.1
Downloading huggingface_hub-0.8.1-py3-none-any.whl (101 kB)
|████████████████████████████████| 101 kB 12.5 MB/s
Requirement already satisfied: Pillow in /usr/local/lib/python3.7/dist-packages (from diffusers) (7.1.2)
Requirement already satisfied: numpy in /usr/local/lib/python3.7/dist-packages (from diffusers) (1.21.6)
Requirement already satisfied: regex!=2019.12.17 in /usr/local/lib/python3.7/dist-packages (from diffusers) (2022.6.2)
Requirement already satisfied: filelock in /usr/local/lib/python3.7/dist-packages (from diffusers) (3.8.0)
Requirement already satisfied: tqdm in /usr/local/lib/python3.7/dist-packages (from huggingface-hub<1.0,>=0.8.1->diffusers) (4.64.0)
Requirement already satisfied: pyyaml>=5.1 in /usr/local/lib/python3.7/dist-packages (from huggingface-hub<1.0,>=0.8.1->diffusers) (6.0)
Requirement already satisfied: typing-extensions>=3.7.4.3 in /usr/local/lib/python3.7/dist-packages (from huggingface-hub<1.0,>=0.8.1->diffusers) (4.1.1)
Requirement already satisfied: packaging>=20.9 in /usr/local/lib/python3.7/dist-packages (from huggingface-hub<1.0,>=0.8.1->diffusers) (21.3)
Requirement already satisfied: pyparsing!=3.0.5,>=2.0.2 in /usr/local/lib/python3.7/dist-packages (from packaging>=20.9->huggingface-hub<1.0,>=0.8.1->diffusers) (3.0.9)
Collecting tokenizers!=0.11.3,<0.13,>=0.11.1
Downloading tokenizers-0.12.1-cp37-cp37m-manylinux_2_12_x86_64.manylinux2010_x86_64.whl (6.6 MB)
|████████████████████████████████| 6.6 MB 61.9 MB/s
Requirement already satisfied: zipp>=0.5 in /usr/local/lib/python3.7/dist-packages (from importlib-metadata->diffusers) (3.8.1)
Requirement already satisfied: chardet<4,>=3.0.2 in /usr/local/lib/python3.7/dist-packages (from requests->diffusers) (3.0.4)
Requirement already satisfied: urllib3!=1.25.0,!=1.25.1,<1.26,>=1.21.1 in /usr/local/lib/python3.7/dist-packages (from requests->diffusers) (1.24.3)
Requirement already satisfied: idna<3,>=2.5 in /usr/local/lib/python3.7/dist-packages (from requests->diffusers) (2.10)
Requirement already satisfied: certifi>=2017.4.17 in /usr/local/lib/python3.7/dist-packages (from requests->diffusers) (2022.6.15)
Installing collected packages: tokenizers, huggingface-hub, transformers, diffusers
Successfully installed diffusers-0.2.4 huggingface-hub-0.8.1 tokenizers-0.12.1 transformers-4.21.1次にモデルをダウンロードして読み込みます。Hugging Faceのアクセストークンが必要となるので、こちらの右上「Sign Up」から登録して、トークン生成ページでトークンを作成します。作成したトークンで下記のコードの「自分のトークンを入力」を置き換えます。
import torch
from torch import autocast
from diffusers import StableDiffusionPipeline
model_id = "CompVis/stable-diffusion-v1-4"
device = "cuda"
access_token='自分のトークンを入力'
pipe = StableDiffusionPipeline.from_pretrained(model_id, use_auth_token=access_token)
pipe = pipe.to(device)Downloading: 100%
1.34k/1.34k [00:00<00:00, 45.6kB/s]
Downloading: 100%
13.4k/13.4k [00:00<00:00, 356kB/s]
Downloading: 100%
342/342 [00:00<00:00, 11.2kB/s]
Downloading: 100%
543/543 [00:00<00:00, 17.8kB/s]
Downloading: 100%
4.56k/4.56k [00:00<00:00, 139kB/s]
Downloading: 100%
1.22G/1.22G [00:20<00:00, 55.0MB/s]
Downloading: 100%
209/209 [00:00<00:00, 2.30kB/s]
Downloading: 100%
592/592 [00:00<00:00, 15.3kB/s]
Downloading: 100%
492M/492M [00:08<00:00, 62.0MB/s]
Downloading: 100%
525k/525k [00:01<00:00, 519kB/s]
Downloading: 100%
472/472 [00:00<00:00, 15.6kB/s]
Downloading: 100%
806/806 [00:00<00:00, 28.1kB/s]
Downloading: 100%
1.06M/1.06M [00:01<00:00, 766kB/s]
Downloading: 100%
743/743 [00:00<00:00, 14.7kB/s]
Downloading: 100%
3.44G/3.44G [01:05<00:00, 58.4MB/s]
Downloading: 100%
71.2k/71.2k [00:00<00:00, 82.3kB/s]
Downloading: 100%
522/522 [00:00<00:00, 16.4kB/s]
Downloading: 100%
335M/335M [00:06<00:00, 53.1MB/s]
ftfy or spacy is not installed using BERT BasicTokenizer instead of ftfy.最後に、画像生成です。下記のpromptに生成元の文章を入れて実行します。この例では、「ハンバーガーを食べているリスの写真」を英語で入力しています。
# 画像生成を実行
prompt = "A photo of a squirrel eating a burger"
images = pipe([prompt], num_inference_steps=50, eta=0.3, guidance_scale=6)["sample"]
# 画像を保存
for idx, image in enumerate(images):
image.save(f"squirrel-{idx}.png")51/? [00:32<00:00, 1.71it/s]画像は以下に保存されます。出力されていなかったら、フォルダの更新アイコンをクリックします。
画像ファイルの三点リーダーからダウンロードできます。
今回出力した画像例。
こんなにリアルで、512×512 pixelとなかなか高画質な画像が生成できるモデルが、公開されたという事実にただただ驚きです。しかも、Colaboratoryを使えばPCの投資も必要無いなんて凄すぎます。

まとめ
Stable DiffusionをGoogle Colaboratoryで実行した手順をご紹介しました。ご参考になれば幸いです。


コメント