
本投稿は、以下の本の実装例を学習用に写経したものになります。詳細について気になりましたら、本を読んでみてください。

つくりながら学ぶ! Pythonによる因果分析 ~因果推論・因果探索の実践入門 (Compass Data Science) | 小川雄太郎 |本 | 通販 | Amazon
Amazonで小川雄太郎のつくりながら学ぶ! Pythonによる因果分析 ~因果推論・因果探索の実践入門 (Compass Data Science)。アマゾンならポイント還元本が多数。小川雄太郎作品ほか、お急ぎ便対象商品は当日お届けも可能。またつくりながら学ぶ! Pythonによる因果分析 ~因果推論・因果探索の実践...
amzn.to
実装例は筆者らのgithubに公開されています。
GitHub - YutaroOgawa/causal_book: 書籍「作りながら学ぶ! PyTorchによる因果推論・因果探索」の実装コードのリポジトリです
書籍「作りながら学ぶ! PyTorchによる因果推論・因果探索」の実装コードのリポジトリです. Contribute to YutaroOgawa/causal_book development by creating an account on GitHub.
github.com
pgmpyのバージョン0.1.23では、上記スクリプトが動作しなかったので以下を参考に修正しています。

PC (Constraint-Based Estimator)
Conditional Independence Tests for PC algorithm:
pgmpy.org
内容
ライブラリインポート
# 乱数のシードを設定
import random
import numpy as np
np.random.seed(1234)
random.seed(1234)
# 使用するパッケージ(ライブラリと関数)を定義
from numpy.random import *
import pandas as pd
データ作成(独立でない場合)
# データ数
num_data = 100
# x1:0か1の値をnum_data個生成、0の確率は0.6、1の確率は0.4
x1 = np.random.choice([0, 1], num_data, p=[0.6, 0.4])
# x2:0か1の値をnum_data個生成、0の確率は0.4、1の確率は0.6
x2 = np.random.choice([0, 1], num_data, p=[0.4, 0.6])
# x2はx1と因果関係にあるとする
x2 = x2*x1
# 2変数で表にする
df = pd.DataFrame({'x1': x1,
'x2': x2,
})
print(df.head())
# 各カウント
print(((df["x1"] == 0) & (df["x2"] == 0)).sum())
print(((df["x1"] == 1) & (df["x2"] == 0)).sum())
print(((df["x1"] == 0) & (df["x2"] == 1)).sum())
print(((df["x1"] == 1) & (df["x2"] == 1)).sum()) x1 x2
0 1 1
1 1 0
2 0 0
3 1 1
4 0 0
58
9
0
33データ作成(独立の場合)
# データ数
num_data = 100
# x1:0か1の値をnum_data個生成、0の確率は0.6、1の確率は0.4
x1 = np.random.choice([0, 1], num_data, p=[0.6, 0.4])
# x2:0か1の値をnum_data個生成、0の確率は0.4、1の確率は0.6
x2 = np.random.choice([0, 1], num_data, p=[0.4, 0.6])
# 2変数で表にする
df2 = pd.DataFrame({'x1': x1,
'x2': x2,
})
# 各カウント
print(((df2["x1"] == 0) & (df2["x2"] == 0)).sum())
print(((df2["x1"] == 1) & (df2["x2"] == 0)).sum())
print(((df2["x1"] == 0) & (df2["x2"] == 1)).sum())
print(((df2["x1"] == 1) & (df2["x2"] == 1)).sum())28
21
28
23独立性のカイ2乗検定
from pgmpy.estimators.CITests import chi_square
# 独立のでない場合
print('(chi_squared, p_value, dof) =',chi_square(X='x1', Y='x2', Z=[], data=df, boolean=False))
print(chi_square(X='x1', Y='x2', Z=[], data=df, boolean=True, significance_level=0.05))
# 独立の場合
print('(chi_squared, p_value, dof) =',chi_square(X='x1', Y='x2', Z=[], data=df2, boolean=False))
print(chi_square(X='x1', Y='x2', Z=[], data=df2, boolean=True, significance_level=0.05))(chi_squared, p_value, dof) = (64.50981396941253, 9.605273040037e-16, 1)
False
(chi_squared, p_value, dof) = (0.0005846494441932367, 0.980709409791787, 1)
True
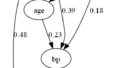

コメント